 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task-Oriented Grasping from Human Activity Datasets
Oct 25, 2019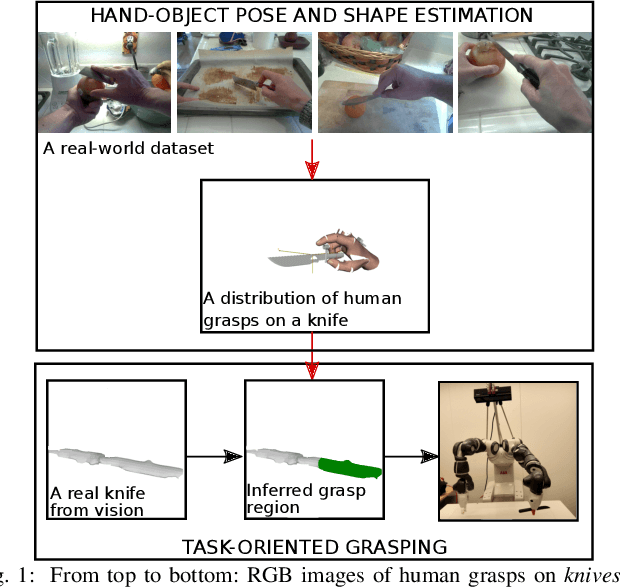
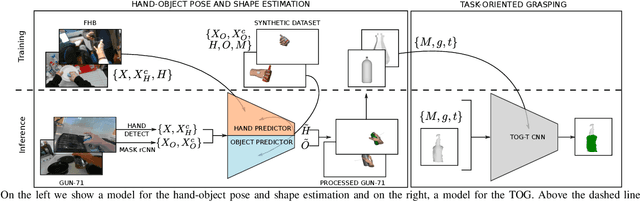
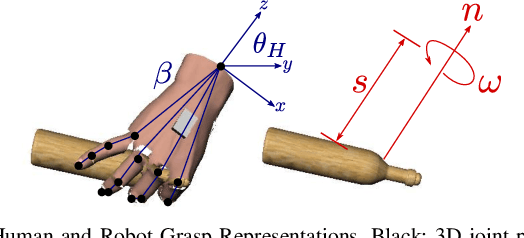
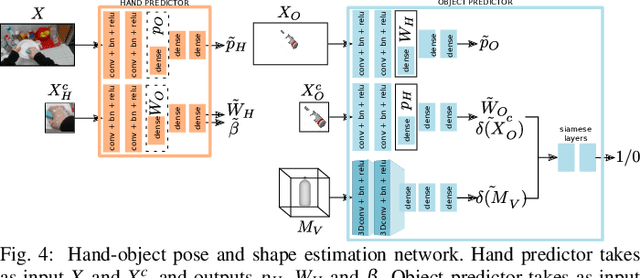
We propose to leverage a real-world, human activity RGB datasets to teach a robot {\em Task-Oriented Grasping} (TOG). On the one hand, RGB-D datasets that contain hands and objects in interaction often lack annotations due to the manual effort in obtaining them. On the other hand, RGB datasets are often annotated with labels that do not provide enough information to infer a 6D robotic grasp pose. However, they contain examples of grasps on a variety of objects for many different tasks. Thereby, they provide a much richer source of supervision than RGB-D datasets. We propose a model that takes as input an RGB image and outputs a hand pose and configuration as well as an object pose and a shape. We follow the insight that jointly estimating hand and object poses increases accuracy compared to estimating these quantities independently of each other. Quantitative experiments show that training an object pose predictor with the hand pose information (and vice versa) is better than training without this information. Given the trained model, we process an RGB dataset to automatically obtain training data for a TOG model. This model takes as input an object point cloud and a task and outputs a suitable region for grasping, given the task. Qualitative experiments show that our model can successfully process a real-world dataset. Experiments with a robot demonstrate that this data allows a robot to learn task-oriented grasping on novel objects.
Learning to Estimate Pose and Shape of Hand-Held Objects from RGB Images
Mar 08, 2019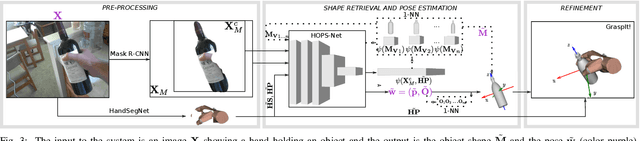
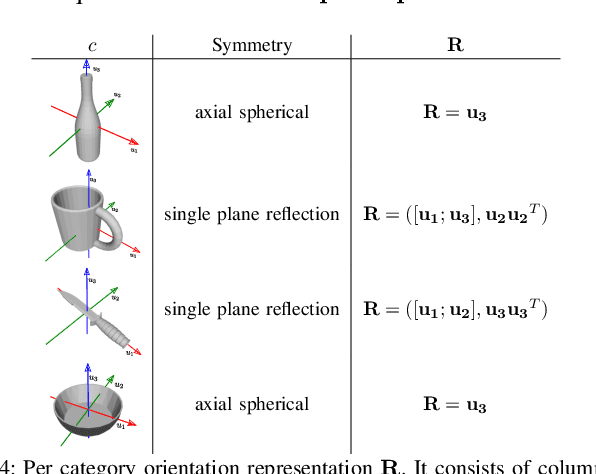


We develop a system for modeling hand-object interactions in 3D from RGB images that show a hand which is holding a novel object from a known category. We design a Convolutional Neural Network (CNN) for Hand-held Object Pose and Shape estimation called HOPS-Net and utilize prior work to estimate the hand pose and configuration. We leverage the insight that information about the hand facilitates object pose and shape estimation by incorporating the hand into both training and inference of the object pose and shape as well as the refinement of the estimated pose. The network is trained on a large synthetic dataset of objects in interaction with a human hand. To bridge the gap between real and synthetic images, we employ an image-to-image translation model (Augmented CycleGAN) that generates realistically textured objects given a synthetic rendering. This provides a scalable way of generating annotated data for training HOPS-Net. Our quantitative experiments show that even noisy hand parameters significantly help object pose and shape estimation. The qualitative experiments show results of pose and shape estimation of objects held by a hand "in the wild".
Global Search with Bernoulli Alternation Kernel for Task-oriented Grasping Informed by Simulation
Oct 10, 2018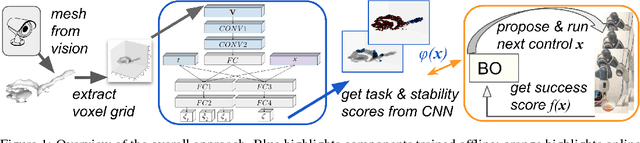
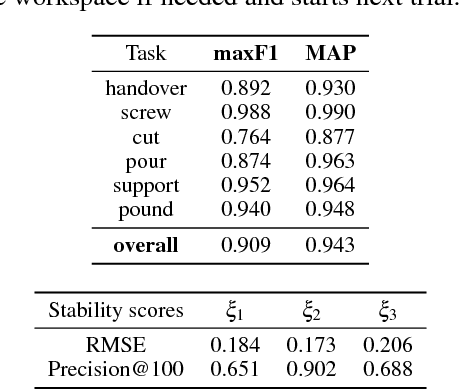
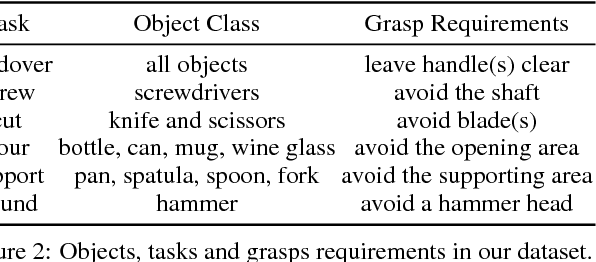
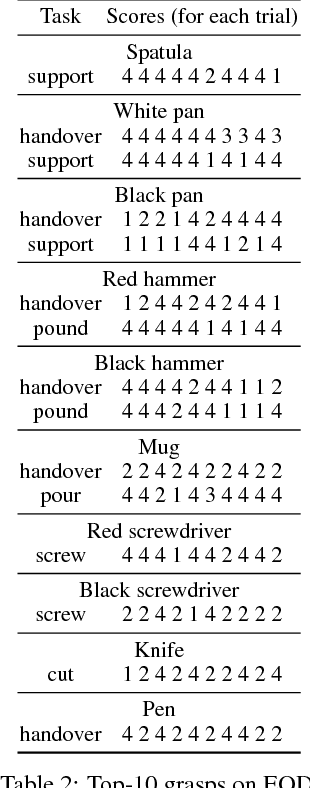
We develop an approach that benefits from large simulated datasets and takes full advantage of the limited online data that is most relevant. We propose a variant of Bayesian optimization that alternates between using informed and uninformed kernels. With this Bernoulli Alternation Kernel we ensure that discrepancies between simulation and reality do not hinder adapting robot control policies online. The proposed approach is applied to a challenging real-world problem of task-oriented grasping with novel objects. Our further contribution is a neural network architecture and training pipeline that use experience from grasping objects in simulation to learn grasp stability scores. We learn task scores from a labeled dataset with a convolutional network, which is used to construct an informed kernel for our variant of Bayesian optimization. Experiments on an ABB Yumi robot with real sensor data demonstrate success of our approach, despite the challenge of fulfilling task requirements and high uncertainty over physical properties of objects.